
Een cloud-to-cloud strategie of een local gateway. Een fundamentele keuze bij het ontwerpen van een energiemanagementsysteem (EMS). Beide kampen kennen fervente aanhangers. Een hybride aanpak klinkt als “best of both worlds”, maar is dat wel zo?
Om te beginnen de definities die ik hanteer:
- Local gateway: Er is een op locatie een EMS systeem aanwezig dat zelfstandig in staat is om lokaal te meten, op basis van deze metingen beslissingen te nemen en apparaten aan te sturen.
- Cloud-to-cloud: De logica voor de aansturing zit in een “EMS” cloud platform. Uiteraard is er wel hardware aanwezig op locatie (de “energy assets” die aangestuurd worden), maar deze hebben zelfstandig een verbinding met het cloud platform van de fabrikant. Het “EMS” cloudplatform stuurt de apparaten indirect aan via de platforms van de fabrikanten.
- Hybride: er is een lokale gateway aanwezig met (fallback) logica. Deze is echter ook verbonden met een cloud platform, waardoor bijvoorbeeld ook apparaten gekoppeld kunnen worden die niet lokaal aangestuurd kunnen worden.
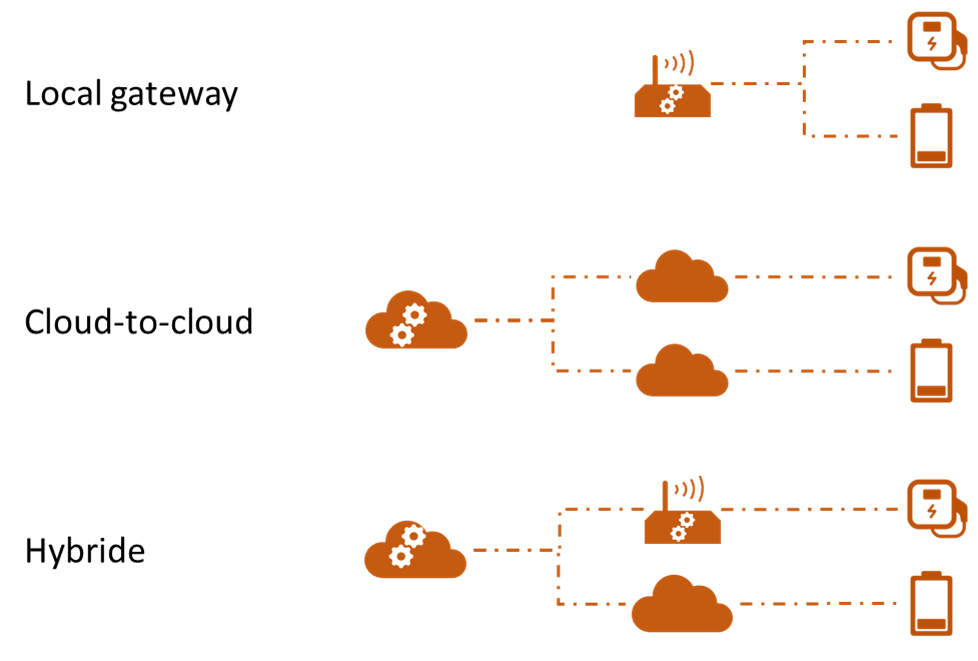
Ik heb de voor- en nadelen van de verschillende opzetten eens onder elkaar gezet, waarbij ik uit ben gegaan van een selectie van non-functional requirements (NFR).
Het toevoegen van een local gateway aan de setup zal de kosten ontegenzeggelijk doen stijgen. Een groot voordeel van een cloud (only) strategie is bovendien de installeerbaarheid. Een klant kan zichzelf onboarden via een app, zonder tussenkomst van een monteur. Met name bij retrofit situaties een belangrijke factor.
Bij cloud-to-cloud systemen ontstaat vaak een afhankelijkheid van vaak meerdere externe partijen die cloud diensten aanbieden. Zij doen niet (of laat) de aanpassingen die je vraagt – en doen juist zonder overleg of goede documentatie aanpassingen waar je níet om vraagt. Vaak leunt een cloudsysteem op meerdere externe aanbieders van infrastructuur die een single-point-of-failure vormen. Dit zie je aan de impact van de recente storingen bij AWS en Cloudflare op andere diensten. Ook op strategisch liggen prijswijzigingen en het stoppen van de dienstverlening op de loer. Met als recent voorbeeld de laders van EVBox die zijn gestopt met werken omdat de achterliggende cloud dienst is opgeheven. Of in het ergste geval: als de rekening om wat voor reden dan ook niet meer betaald wordt, zal een clouddienst direct uit de lucht gaan. Niet veel later zijn de backups en broncode gewist, waardoor een restore praktisch is uitgesloten. Veel van deze risico’s kunnen gemitigeerd worden, maar het is niet verstandig ze te negeren.
In tegenstelling tot decentrale local gateways, zijn cloud systemen per definitie centraal. Dit betekent dat een storing in één van de schakels impact zal hebben op een groot deel van de populatie. Als de klantenservice vervolgens overspoeld wordt met vragen en je bovendien beperkt invloed hebt op het oplossen van het probleem, is dat geen prettige situatie kan ik uit ervaring melden. Of wellicht nog vervelender: het signaal aan de VPP om af te gaan regelen is nog net doorgekomen voor de uitval, maar inmiddels zou je eigenlijk op willen regelen. Veel apparaten vallen na een time-out terug naar een standaard profiel, maar tot die tijd kan de schade aan de onbalanspositie aardig oplopen. Ik doe hiermee overigens geen uitspraak over de betrouwbaarheid, maar wel over de weerbaarheid in geval van storingen (“resilience”).
Voor sommige use cases is een snelle regeling van belang, met weinig vertraging tussen de metingen en uit te voeren acties die de logica bedenkt. Dit wordt ook wel latentie (“latency”) genoemd. Bijvoorbeeld als het gaat om load balancing, solar charging of zero-feedin curtailment. Een cloud-to-cloud systeem is hiervoor eenvoudigweg te traag. Ik zie regelmatig dat deze use cases pas later in beeld komen en dus niet meegenomen worden bij de oorspronkelijke architectuurkeuze. Het niet hebben van een load balancer kan bij een multi-asset aansturing al snel een vervelend probleem worden.
Ieder EMS systeem is volop in ontwikkeling, waardoor aanpasbaarheid een belangrijke factor is. Hierbij is een cloud-only systeem zeker in het voordeel. Er zijn steeds mooiere technologieën om IoT devices over-the-air (OTA) te updaten, maar dit legt het af tegen de continuous deployment mogelijkheden in de cloud. Alleen al omdat niet alle devices altijd online zijn (soms om de simpele reden dat ze in een magazijn liggen).
Als het gaat om testbaarheid, wordt vaak gevreesd voor local gateways. Ik denk dat dit niet terecht is. Het testen van logica kan complex zijn, maar hierbij maakt het niet uit waar deze logica draait. Ook embedded software kan prima geautomatiseerd getest worden met een goede dekkingsgraad. De sleutel zit in een goede component-based teststrategie.
Samengevat:
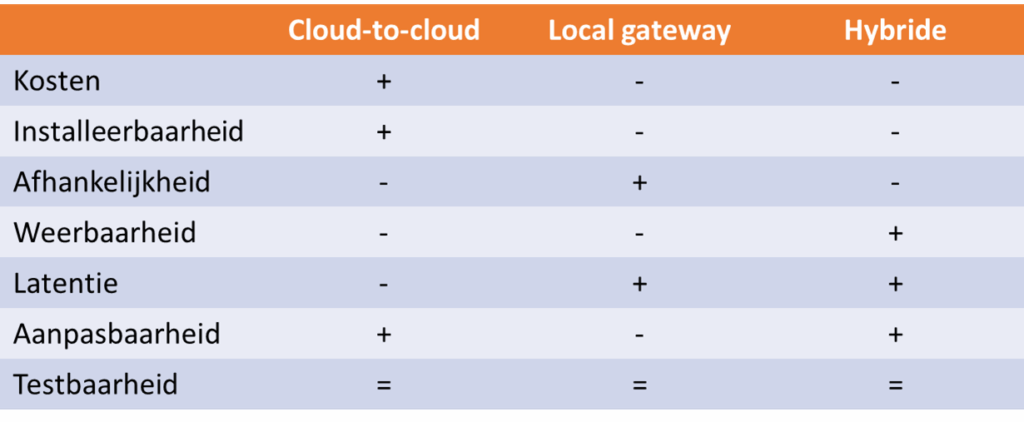
Merk hierbij op dat het te simplistisch is om te stellen dat een hybride setup “best of both worlds” is. Deze uiteenzetting geeft geen eenduidig antwoord op de vraag welke architectuur het beste is. Dit hangt geheel af van de weging van de verschillende NFR’s, waarbij zaken als te ondersteunen use cases en de schaal waarop uitgerold wordt belangrijke factoren zijn.
Ik hoop hiermee wel een universeel framework neergezet te hebben waarmee een goede (her)overweging gemaakt kan worden, waarbij alle relevante aspecten worden meegenomen.